
The Dilemma of Decentralized Storage Ecosystems
The decentralized storage ecosystem is booming, but with this growth comes a dilemma: As meaningless data is allowed and even incentivized, it leads to lots of useless data in the ecosystem. Besides, the advantage of blockchain-based decentralized storage technology is not necessarily in providing more storage or better privacy, but in creating an unprecedented ability to share reliable data without a third party.
Before the advent of decentralized storage, there was very little data that could be credibly shared based on Ethereum, and the data was expensive. After the emergence of decentralized storage, with the help of the InterPlanetary File System (IPFS for short), there is theoretically an infinite amount of dependable shared data. This has huge implications for AI data in particular.
In 2021, the global AI market was $3 trillion in value, with an annual growth rate of 20%. In the entire AI market, 15 to 30% of the capital is invested just in data labeling every year, and the scale of this business is growing at 30% per year.
Underlying this growth is the fact that algorithms are no longer the key to innovation in AI intelligence. Instead, it’s now the quality of the data used for AI training that matters. Due to the sharp increase in demand for data, the AI data industry faces constraints, including:
- Rising labor costs: The demand for data is becoming more and more specialized. From recognizing voices and pictures to labeling data from various industries such as healthcare, finance and education, there are greater demands on the knowledge base of labelers.
- Rising business costs: Data-labeling companies are unable to enjoy data ownership or to share in the realization of the benefits of the delivered data. They can only rely on labor to maintain current cash flow, with no prospect of appreciation and expansion. With more competition in the industry, most labeling companies fail to operate at full capacity, increasing the potential of no work for employees.
EpiK Protocol Making AI Data Useful
There are two mainstream solutions to this AI data labeling dilemma: The gig economy and the sharing economy. The gig economy uses crowdsourcing to label data, while the sharing economy helps people get revenue if they participate in data contribution.
Both these solutions work best with decentralized storage and are the best way that trusted data sharing capabilities can be applied. These two solutions are the foundation of EpiK Protocol, which combines decentralized storage and AI data to create the first decentralized storage protocols for AI data in the world.
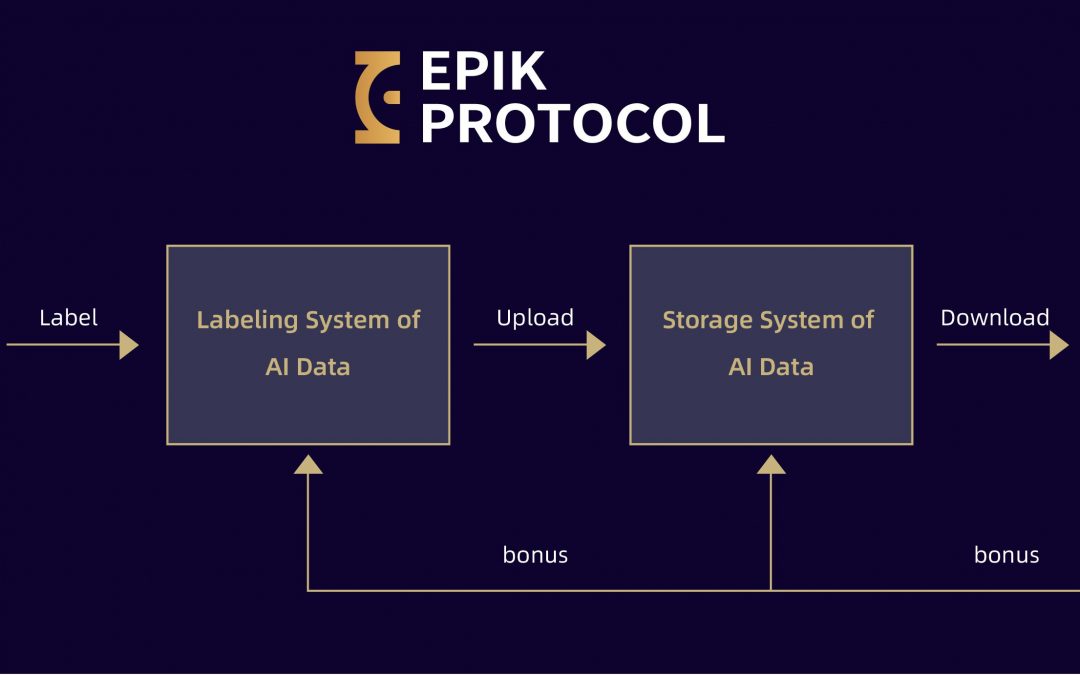
A typical EpiK Protocol runtime flow is shown in the following image:
The data from different data sources are labeled by the AI data labeling system provided by EpiK, and those who participate in data labeling and data acceptance can get EpiK’s token EPK. The accepted data are stored in the AI data storage system provided by EpiK for decentralized storage, and the devices that participate in data storage can also get EPK.
When applications need to use the data, they pledge EPK to access the data. The EPK obtained for the contribution of data becomes the equity of the data. The greater the demand for data, the higher the demand for EPK. The EPK will thus appreciate in value, and the EPK holder will benefit.
Decentralized storage requires a sustainable and efficient data production mechanism; the huge amount of AI data can fill this demand. At the same time, the AI data market needs a platform to run a sharing economy—and the powerful data authentication capability of decentralized storage can resolve this problem.
Through the integration of IPFS storage technology, a token incentive mechanism and DAO governance model, EpiK Protocol creates a global, open, autonomous community with four core capabilities of trusted storage, trusted incentives, trusted governance and trusted finance. It allows global community users to work together at an extremely low management cost, continuously producing high-quality AI data that can be jointly built and shared. This will broaden the understanding of AI, and hasten the arrival of the era of cognitive intelligence.




 steals Dogecoin’s thunder")







